Implementation on a neural network architecture
Coneural > Ioana Goga > PhD
research > Implementation on a neural network architecture
Visual attention mechanisms
The attentional module consists of a neural network that integrates top-down
attentional cues with bottom-up saliency of the objects perceived (see Figure
5).
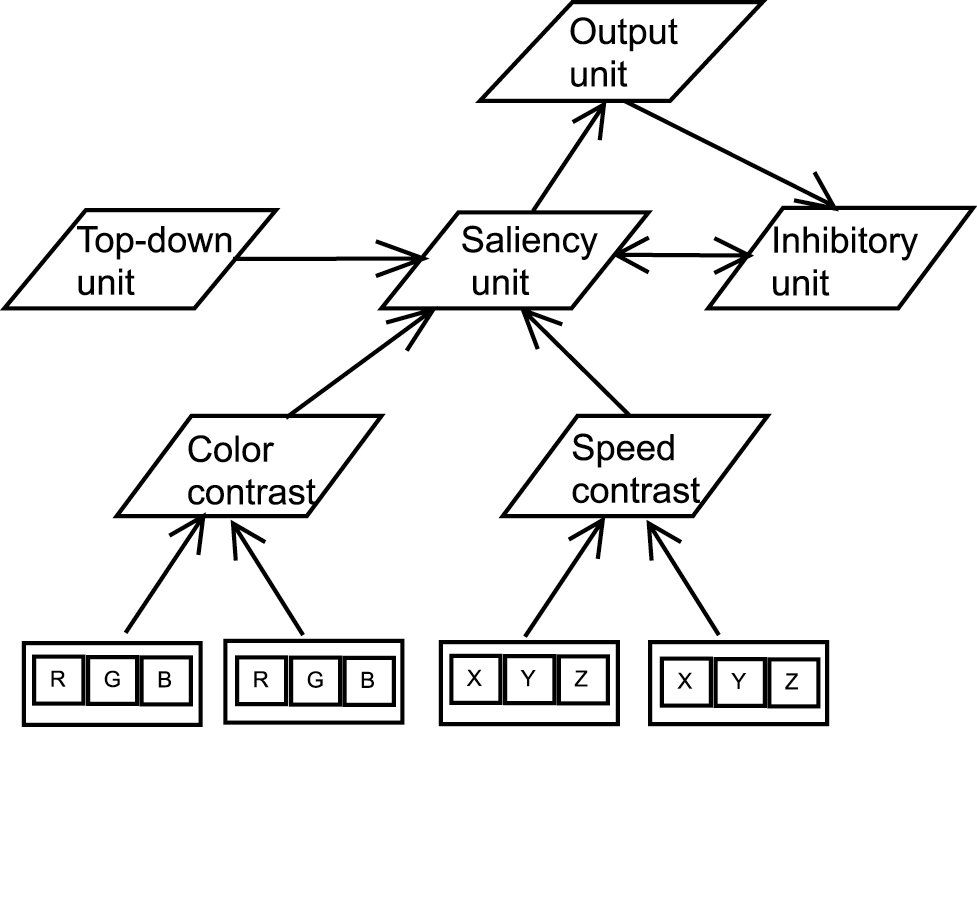
Figure 5. Basic computational unit of the attentional module. For each object
location, saliency is computed based on the contrast of two low-level
features: color and speed. Inhibition of return allows the switch of attention
from the currently attended location. The top down cues are: the direction of
the demonstrator's gaze and the position of the demonstrator's hand.
The location of the focus of attention results from a process of multiple constraints
satisfaction. The constraints are defined based on psychological data showing
that: (1) infants follow the gaze of the caretaker, (2) they prefer watching
moving objects vs. static objects, and (3) they gaze hands or objects with a
high color contrast over other static objects (see Goga
and Billard, 2006c for a detailed description of the attentional mechanism
implementation). The behavior exhibited by the learner during the demonstration
of the seriate cups task can be seen in the demo bellow.
Object recognition module
The object recognition module is responsible for the visual awareness of the
objects existent in the environment. An object recognition unit corresponds
to a distinct location of each object. A subnetwork is formed if several objects
exist at the same location (see Figure 6).
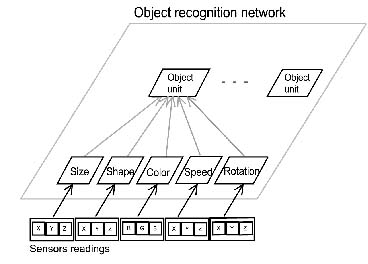
Figure 6. Object recognition network corresponding to one location in space.
Recognition of an object is made upon integration of five features: size, shape,
color, speed, and rotation angle. If an object moves along a trajectory, the
network architecture does not change.
The weights in this layer learn the representation of the objects existent
at some location. The module allows detection of events occurring on any dimension/feature
of the system. Whenever a new event is detected, the superior level (see bellow)
is called to handle the occurrence in the system of the new object/event.
Cell assembly module
A cell assembly (CA) receives two types of signals: one from the saliency map
and one from the object recognition module. When a new event is detected on
a location that is on the focus of attention, the cell assembly layer is informed
and takes a decision:
- creates a cell assembly unit to represent the new category or
- learns the event in the representation of an existent category.
Three set of weights are adapted at this level, corresponding to:
- learning of the category/CA features
- learning of the precedence relationships
- learning of size relations.
For a detailed description of the learning algorithm see Marian
& Billard (2004) and Goga and Billard
(2006a).
|