|
|
|
 |
|
Dynamic simulation with humanoid-robots on XANIM
Coneural > Ioana Goga > PhD
research > Dynamic simulation with humanoid-robots
We implemented the computational model of the seriated cups task, on a dynamic
simulation of a child-caretaker pair of humanoid-robots. We used Xanim simulator
(Schaal, 2000) to model a pair of 30 degrees of freedom (Head 3, Arms 7*2, Trunk
3, Legs 3*2, Eyes 4 D.O.F). Xanim is created using the simulation package SL
(Schaal, 2000). SL has a modular structure that includes a motor servo, used
to read the current state of the robot/simulation and to send commands to the
robot/simulation; a task servo that allows switching between different tasks;
a vision servo to collect data from camera systems; and inverse dynamics and
inverse kinematics servos to allow control of the robot from Cartesian states.
The implementation of the model is described in more detail in Marian
& Billard (2004).
Pairing behavior corresponding to the first developmental stage
As explained in the description of the computational
model, what the agent learns during the demonstration of the seriate cups
task is a result of the functioning of three mechanisms: basic categorization,
joint attention and localized representation. The joint attention mechanism
is necessary to focus the attention on selected objects and to decrease the
amount of information learned at any time moment. An assumption of our model
is that during the first seriation developmental stage, the cognitive system
of the learner is characterized by a low vigilance parameter. By this
we mean a low capacity to make fine distinctions between the objects placed
in the focus of attention. This determines basic categories to occur and leads
to the formation of two internal goals: <hand
grasps cup> and <place
cup into cup>.
During retrieval, the internal model activates sequentially the two goals.
Each active goal drives the actions of the agent towards its satisfaction. At
this stagem, the simplest behavior achieved by the agent is to pair two cups.
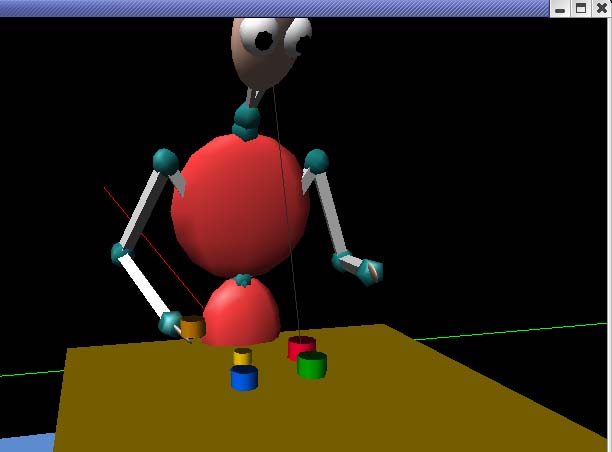
Figure 7. Pairing of two cups. The cup from position 2 (brown cup) is grasped
and carried to position 3 (blue cup).
Choice of the cups
The choice of the cups to be combined results is a function of multiple constraints
satisfaction (size, saliency and economy). There are different possible settings
of the constraints probabilities:
- one possible setting corresponds to a model where saliency has the higher
probability, which means that the first selection criterion is the object's
saliency. It can lead to various behaviors, as a function of how the other
two constraints are satisfied. Figure 8a shows how the most salient object
in the scene is chosen as an acting cup (blue cup from position 3), while
the recipient cup is chosen to minimize the path (proximity constraint). Figure
8b shows how the acting cup, (i.e., the most salient object), is brought to
position 4 (green cup), in order to satisfy size constraints.
(a) 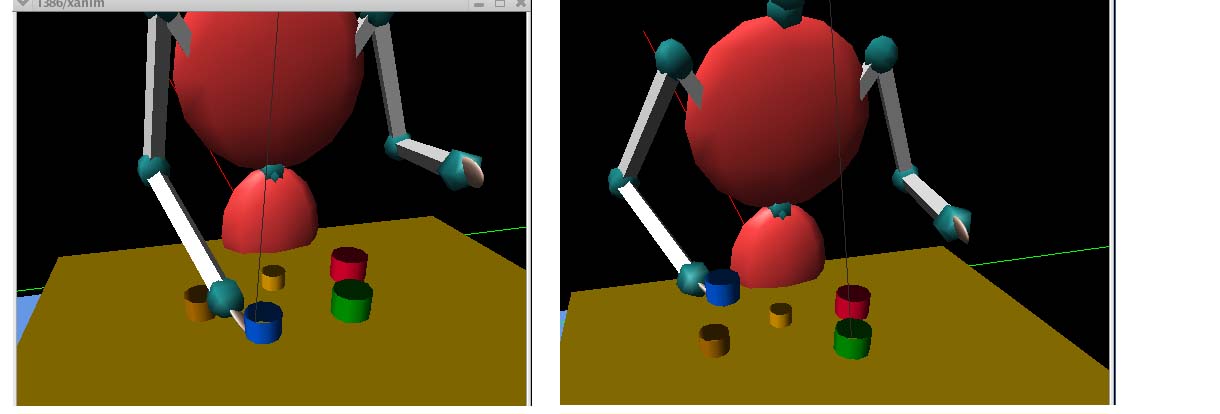
(b) 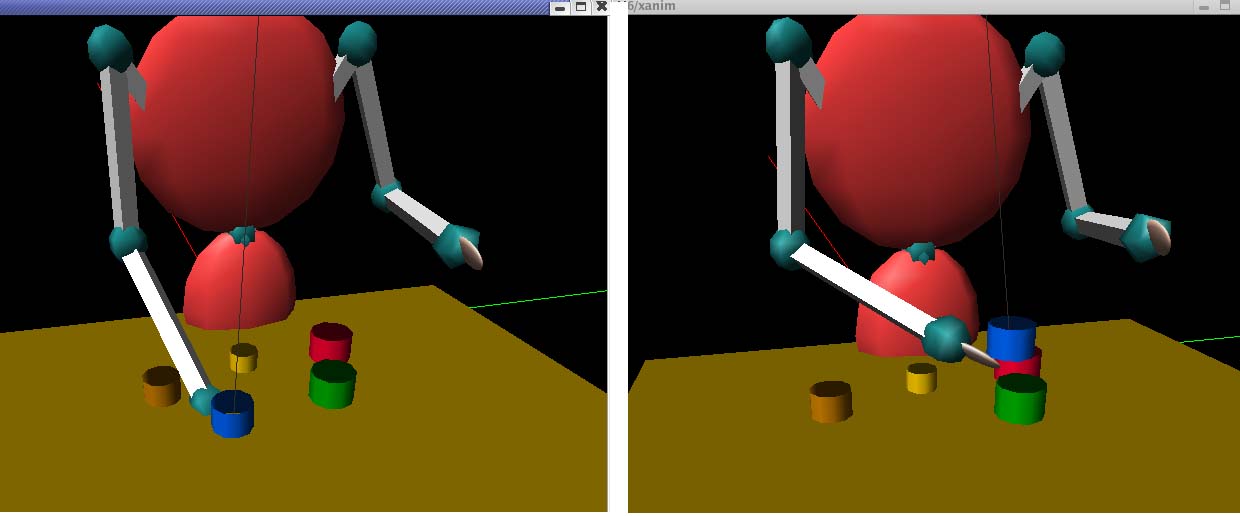
Figure 8. Saliency driven model. The most salient object becomes the
acting cup and it is nested with different cups in order to satisfy (a) proximity
constraints; or (b) size constraints.
- another setting corresponds to an internal model which optimizes size consonance.
To do this, the agent compares internally several objects located in the focus
of attention and picks the acting and the recipient cups in such a way to
satisfy the constraint: "place a smaller cup into a larger cup".
Note that children usually satisfy size constraints, but do not maximize size
consonance at this stage (i.e., infants usually embed the smallest cup with
some larger cup, probably proximity issues being also considered). See behavior
illustrated in Figure 9.
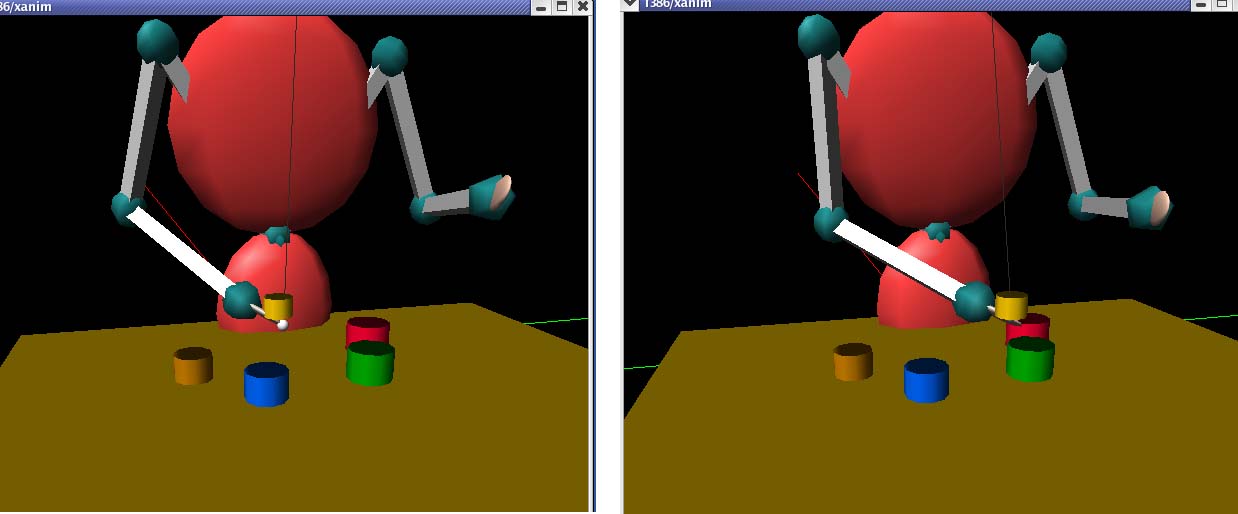
Figure 9. The acting and the recipient cups are chosen to increase size
consonance value.
Two pairs and the transfer of one cup
When the hand with the acting cup reaches the position of the target cuip,
the system must choose between two possible actions: (a) drop the acting cup
and form a pair; (b) hold the acting cup and move the hand. The satisfaction
of the goal <place cup into cup>
leads the system into a final state (system halts, as seen above). By
contrary, if from different reasons the goal <place
cup into cup> is not satisfied by the current embedding, then it remains
active and it drives the behavior of the system until its completion.
By keeping the goal <place cup into
cup> unsatisfied, two types of behavior can result:
- one pair is formed and the system continues by choosing another acting cup
to form a new pair. This type of behavior is specific to the transition from
the first to the second developmental stage.
- the acting cup is not dropped at the target position, and the system continues
by transferring the cup through several recipient positions. See the transfer
of one cup through different positions in Figure 10.
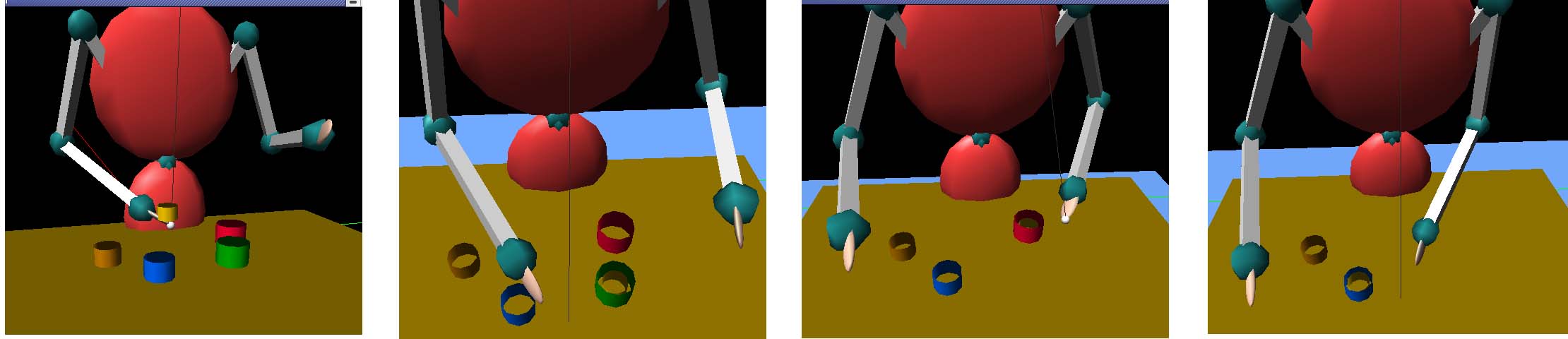
Figure 10. The yellow cup from position 1 is transferred through several
positions. First, it is brought to the position 4 (green cup); second, it is
brought to the position 5 (red cup); finally it is brought to position 3 (blue
cup). At each move, the recipient cup is chosen to maximize size consonance.
This setting of the parameters favours the acting of the system towards the
satisfaction of the first goal <hand
grasps cup> and determines the unsatisfaction of the second goal,
what leads to the transfer of the initial cup through several target positions.
From simulation simplicity reasons, a previously visited cup falls down from
the table, and it is not visible anylonger.
In our model, the concept of the "object as an extension of hand"
is naturally emerging by setting two parameters: (1) set a higher priority for
the satisfaction of the goal <hand
grasps cup> compared to the satisfaction of the goal <place
cup into cup>, and (2) set a high probability for the conservation/proximity
constraint.
Pot strategy corresponding to the second developmental stage
The transition from the pairing to the pot strategy can take place in two ways
(in our view):
- increase the number of the specific goals that are learned during the demonstration
of the task (i.e., a sequence of sub-goals)
- preserve an internal model with only two goals, but increase the information
stored within each goal representation (i.e., two fully specified goals)
The assumption of this model is that the second stage is characterized by increased
vigilance and memory resources, which are used to learn more information about
the goals of the imitation task. During the second stage of development, cognitive
resources are employed to learn more about the goal <place
cup into cup>. This leads to an increased capacity to remember that
several cups (instead of two) have been embedded. Only during the third developmental
stage, attentional and memory resources are employed to learn more about the
<hand grasps cup> goal.
These computational assumptions were inspired by experimental data showing that
infants learn what to imitate, before learning how to imitate.
The behavior of the agent in the second developmental stage is oriented towards
the maximization of size consonance, computed for all the objects stored in
the representation of the final state goal. With each new pair formed, the total
consonance increases, and makes less probable behaviors such as, the transfer
of one cup through several positions. As a function of how much time the system
spends to compute the consonance and how this is computed, different behaviors
can result: a tower vs. a nest; a pot containing all the cups vs.a pot with
two or three cups. See the nesting of three cups illustrated in Figure 11.
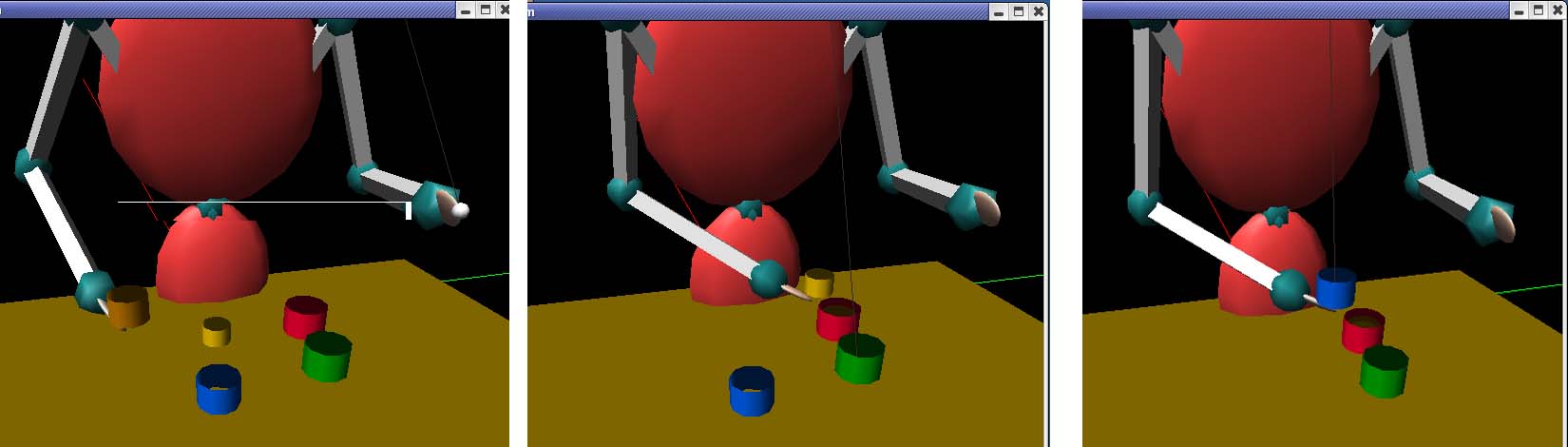
Figure 11. A pot with cups is formed at position 5 (red cup). First
it is embedded the brown cup from position 2. Next, the yellow cup from position
1, followed by the blue cup from position 3. Size constraints are satisfied
with respect to the acting cup and the recipient pot cup. A tower may result
(not shown graphically), because consonance is computed between visible cups,
and the size of the already nested cups is not taken into account.
Originality of our account
We would like to point out one important aspect of our account. At the first
sight, the seriate nesting cups task may be regarded as a sequence learning
problem. For instance, one may consider that the transfer of the cup through
different positions is a result of learning a sequence of actions or positions.
Similarly, one may consider that the formation of the pot in the second developmental
stage is the result of learning the sequence of cups to be embedded. Our explorations
also included an approach based on sequence learning (see Marian
& Billard, 2004).
Today, we came up with a different solution, which is not based on sequence
learning or reproduction. The internal model of the imitator consists of two
interconnected goals, which can be activated each, by a set of predecessors.
The sequencing like behavior results from the process of multiple constraints
satisfaction that takes place during retrieval, and it is not reproduced from
a stored sequence structure. We believe that by storing information in a set
of constraints, instead of learning the explicit sequence, the system is capable
of reproducing the variety of behavior shown by human infants. To exhibit both
consistency and variety of behavior represents an important achievement for
an epigenetic robot.
|