|
|
|
 |
|
A developmental computational model of the nesting cups behavior
Coneural > Ioana Goga > PhD
research > Developmental computational model
Up to present, we are not aware of the existence of any computational model
for the seriate nesting cups behavior. The aim of such a model is twofold:
- it should be able to reproduce the limitations characteristic to the infants'
seriation developmental stages
- it should be able to reproduce the variety of behaviors observed within
each stage of development.
To account for both consistency and variety of behavior, we propose that:
- differences between developmental stages can be accounted for by the learning
model
- variety of behavior within a stage of development is a consequence of multiple
constraints satisfaction during retrieval
Note that the hypotheses and assumptions presented here are a result of several
exploratory experiments (see Marian
and Billard, 2004), which led us to the idea of separating learning and
retrieval, in order to solve the issue of consistency vs. variety of behavior.
A. Learning model
During demonstration of the nesting cups task, the learner forms an internal
goal of what should be imitated, as a function of the way its cognitive system
processes information. Drawing on experimental data, we selected three computational
mechanisms available to human infants in the early stages of development, which,
we believe, can account for consistent differences in behavior:
- attentional focus, the learner learns only properties or relations
existent between focused objects
- basic-categorization, the learner reduces the complexity of the problem
by creating and managing large categories of data
- localized representations, the learner builds distinct visual neural
representations based on distinct locations of the objects
To have these three functionalities at work, several components had to be modeled
and implemented..
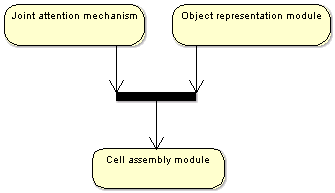
Figure 3. Computational components required for the modeling of seriate
nesting cups behavior. The joint attention mechanism deploys the attention of
the learner according to a set of psychological inspired constraints. The object
representation module ensures the visual awareness of the objects and the detection
of new events. The cell assembly layer learns categories of object or event
compounds and learns precedence relationship between these categories. See here
for a description of the implementation of the model.
Learning of the seriation ability takes place at the cell assembly level. The
algorithm functions on similar principles with Growing K-Means Clustering (GCM)
and Adaptive Resonance Theory (ART). Note that instead of using the concept
of cluster or category, we use the more neurobiologically plausible concept
of cell assembly. For a detailed description of the model architecture, of the
concepts used and of the learning algorithm see Goga
and Billard, 2006
B. Retrieval model
Imitation of the seriate cups task is driven by the internal model of the system
acquired during learning and should satisfy three types of constraints (see
Figure 4):
- size relations, acquired during learning and stored in the weights
of the internal model
- saliency properties that focus the attention preferentially on the
most salient objects
- conservation, reflected in the choice of the minimal path towards
the acting/recipient cup and in the preference of the system to remain in
a state with minimal energy.
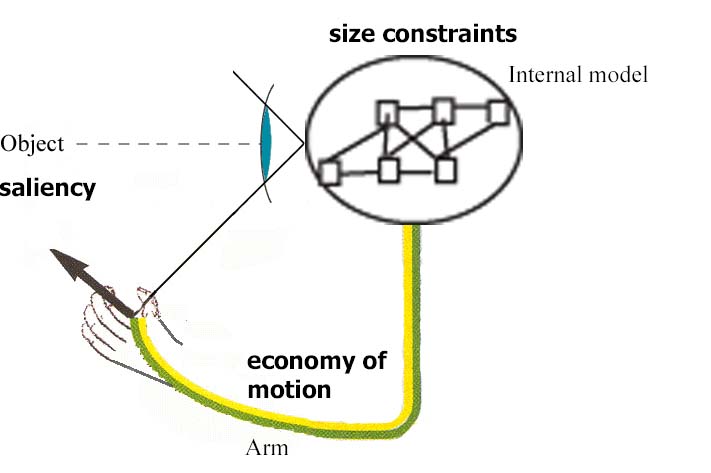
Figure 4. The execution by the learner of the nesting cups task, is driven
by the satisfaction of three types of constraints: size, saliency and economy/conservation.
There are several concepts important during retrieval (for a detailed description
of the algorithms and concepts see Goga
and Billard, 2006). We define:
- a goal, as a hidden cell assembly, that is, a cell assembly which
is not satisfied by the current state of the world (i.e., <a
hand carrying a cup>, when the hand does not hold anything). The
actions of the agent during the imitation phase, are driven towards the satisfaction
of activated goals.
- cognitive dissonance is a state of tension that the agent is trying
to reduce. The consonance is computed based on the size relation weights that
have been learned, and the system acts towards the maximization of the total
consonance.
During retrieval, the attention of the agent is continuously shifting between
the most salient objects in the scene. The visual awareness of an object or
a set of objects activates the corresponding category from the cell assembly
(CA) level. Some CAs are called hidden, because they correspond to categories
which are not satisfied by the current state of the environment (i.e., <cup
into cup>, when all cups are placed at different locations). When
all the predecessor constraints are met for a hidden CA, this is activated and
becomes a goal. Actions are chosen to satisfy the current goal of the system,
while the acting and the recipient cups are chosen to satisfy different settings
of the probabilistic constraints (i.e., size, saliency, economy).
Here is shown the behavior of the agent
reproducing patterns of activity characteristic to thefirst developmental seriation
stages.
|